Offline First
I gave a talk at DrupalCon Dublin 2016 on the subject of Offline First. In it I covered enhancing a Drupal website for users with poor or non-existent network connectivity.
Here are some notes along with links to the resources I mentioned:
Background
I’ve been involved in developing native apps over the last few years. A lot of this material has been shaped by what I’ve learned from that.
When it comes to working offline, we expect that mobile apps do, and the web doesn’t. By definition, mobile apps have always had to contend with a non-reliable network, whereas HTML-based websites were originally used only on fixed connections, and have had to adapt since the arrival of smartphones.
People expect that when you touch an app icon on the home screen of your phone, it will work, regardless of where you are. That’s where we need to get to with the web.
There seem to be a lot of apps out there that aim to provide the same content as a website, but accessible offline. This is a big duplication of effort - you’re writing several front ends. All are using the same hardware, the same network (with its frailties) and the same data (albeit perhaps in a different format).
The only difference is the software, and browsers are now starting to provide for this.
In future, perhaps many of these apps will become obsolete. Instead, we’ll develop offline-capable websites.
Here’s a small demo site for a conference. It’s very basic, just a few pages for the schedule and talk descriptions. To keep things simple, I’ve only dealt with GET requests and for non-personalised content.
This is a good candidate for improvement - can we enhance it and turn it into something a delegate can rely on?
Let’s make all the content available as soon as a visitor downloads the first page. Later on, they can go back regardless of whether or not they have internet access.
Browser support
For current browser support, see the “is service worker ready?” website.
Don’t let this stop you though. Offline capability can be added as a progressive enhancement. People using a browser that doesn’t support it will still have the same experience they had before.
Service Worker
The key piece of the puzzle is the service worker.
We can think of this as a proxy server running on the user’s device. It is a programmable layer between document and network. Like having a little mini web server on your phone.
The service worker can do a number of things - for now, we’ll focus on two: intercepting network requests, and providing programmable access to a cache.
To get started, we register a service worker once the page loads:
if (navigator.serviceWorker) {
navigator.serviceWorker.register('/sw.js', {scope: '/'});
}
We also define the service worker itself, but for now this can be empty:
sw.js:
// empty
That’s the bare minimum. Once this is up and running, any subsequent pages within that scope will be loaded by the service worker. And those pages will in turn use the service worker for all their network requests - CSS, images, scripts, web fonts, AJAX callbacks, analytics tracking etc.
Admittedly, this service worker isn’t doing anything at the moment, but it is running, and we can inspect it using the browser’s developer tools:
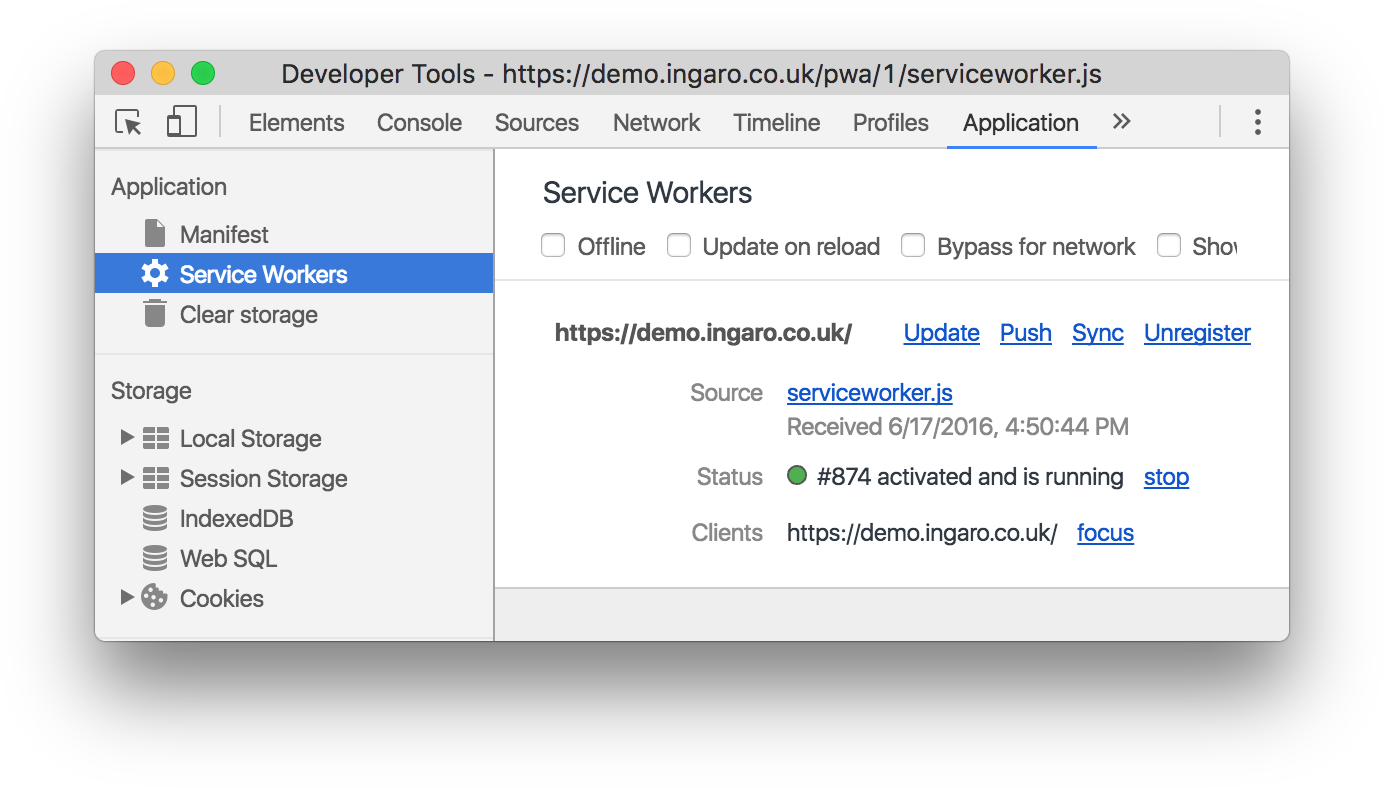
Let’s have a look at how the service worker can be customised:
Service workers are event driven. The install event occurs when the service worker is first installed, just after the initial page is loaded. We can handle this event and preload things we know we’ll always want offline, like CSS.
self.addEventListener('install', function(event) { ... });
The fetch event occurs whenever a service worker enabled page makes a request. This is where things get interesting, because we can define what happens when the page makes different kinds of request.
self.addEventListener('fetch', function(event) { ... });
Helper APIs
Promises
Many of the APIs we’ll use are asynchronous, and use promises. Promises are widely used in functional programming, but can be a little hard to get your head around at first. A promise provides us with a way to ask a question, and get something back before that question has been answered. The promise will either resolve (in which case the “then” function is run), or reject (in which case the “catch” function runs), like this:
doTimeConsumingTask(...)
.then(function(result) {
// we were successful
})
.catch(function(err) {
// we were unsuccessful
});
Fetch API
The fetch api provides functionality that’s similar to jQuery’s AJAX functions.
fetch(new Request('/some/url', {method: 'GET'}))
.then(function(response) {
// we were successful and we have a Response object
})
.catch(function(err) {
// we were unsuccessful
});
Cache API
The cache api gives us a programmable cache, where we can store/retrieve things.
cache.match(request)
.then(function(response) {
if (response) {
// found it
}
else {
// didn't find it
}
});
It’s more flexible than the browser’s default cache - we can access stale content, a key requirement for offline.
We can inspect this cache using the browser’s developer tools:
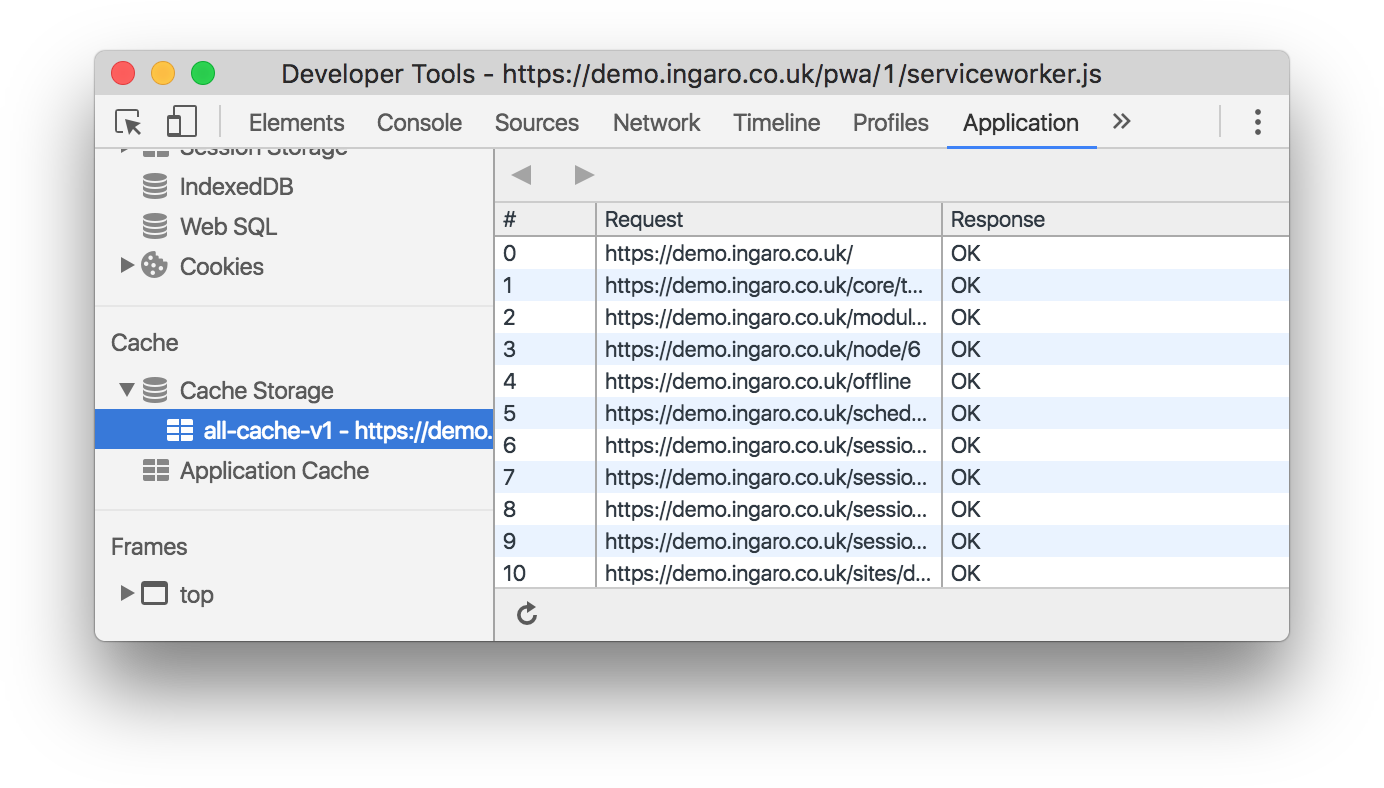
Fetch strategies
The offline cookbook gives a good overview of different strategies for fetching and serving content.
Network only
This is the status quo. If we don’t do anything, the service worker will do this:
self.addEventListener('fetch', function(event) {
event.respondWith(fetch(event.request));
});
Network first, but with a cache fallback
We can improve things by falling back to the cache if the network fails. If the response is cached, we can give the user that. Otherwise, we’ll fail as before.
// function to run when the network request succeeds -
// store a copy of the response in the cache for use next time
// and return the response that we downloaded
var onNetworkSuccess = function(response) {
var responseCopy = response.clone();
caches.open('my_cache').then(function(cache) {
cache.put(event.request, responseCopy);
});
return response;
};
// function to run when the network request fails -
// try and get one from the cache, if we have it.
var onNetworkError = function(error) {
return caches.match(event.request);
};
fetch(event.request)
.then(onNetworkSuccess)
.catch(onNetworkFail);
This is better, but it doesn’t provide an instant response to the user. We need to rethink what we mean by offline:
- intermittent connectivity that comes and goes, e.g., on a train going though a tunnel
- weak mobile signal in a remote location
- bad wifi
- corporate firewalls
Sometimes pages take a while to load. HTTP is a reliable protocol but it runs on top of an unreliable physical infrastructure. TCP/IP works by sending packets out and waiting for packets to come back. If they haven’t come back after a certain time, all the operating system (and therefore the browser) can do is give up and timeout.
So online/offline isn’t a binary state, and it takes time to determine. Our users may well have less patience and decide themselves before the timeout.
What is offline first?
To get round this, we should try to give the user something immediately, even if it’s old. Then see if what they asked for has changed, and deal with that accordingly.
Let’s assume the user is offline, and treat the network as an enhancement.
This might sound a bit crazy, but we can draw parallels from visual design - we used to think of layout as an intrinsic part of a website. Now we assume mobile first and treat layout as an enhancement.
The native twitter app is a good example of offline first. When you open the app, you see your timeline straight away. At the same time, the app starts looking for new tweets, and pops up a “New tweets” icon once (and if) they become available:
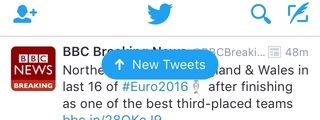
You can engage with the app straight away and start reading, rather than staring at a progress indicator while the most up to date content loads.
This is the whole idea behind offline first: show the user something straight away, even if it’s old. We’ll worry about updates later! This is usually (but not always) better than nothing at all.
Ideally, we want to decouple the user’s interaction from network requests.
Cache first, with network fallback
This time, we look at the cache first, and only if that doesn’t succeed do we go to the network. If we get a cache hit, we also start a network fetch so that we can update the cache. Crucially though, we don’t wait for this - we return the cached content, stale or not:
cache.match(request).then(function(cachedResponse) {
if (cachedResponse != null) {
// if we got a cached response we will return it,
// but we also want to fetch another copy so that
// our cache is kept up to date
fetch(request).then(/* add to cache */);
return cachedResponse;
}
else {
return fetch(event.request).then(/* add to cache */);
}
});
Informing the user about updates
So far, this method of serving stale content and then updating it ready for next time is ideal for CSS, images etc. For actual content it’s good too, but we should make sure we don’t show the user something old without them knowing.
We don’t have access to the DOM within the service worker, but can we can communicate with the window/tab that’s showing it (the client), by sending a message. It looks a bit like this:
client.postMessage({
type: 'updatedContent',
url: response.url
});
Then in the document’s script, we can set up an event handler to respond to those messages:
navigator.serviceWorker.addEventListener('message', function(event) {
// show a message
});
See the Clients API on MDN for more details.
If the response has changed, the user has the option to reload the page. If not, we just do nothing - they got their page immediately and it was up to date.
In order to get this to work, the server needs to be configured to send ETag headers. The ETag value is a hash of the actual content. This provides us with an easy way to tell if a response has changed form what we have cached.
Drupal
Some early work has been done on a progressive web apps module for Drupal 7 & 8. You need to specify (in configuration) the URLs that you want to be available offline. The module attempts to figure out all the offline resources you need build a service worker script for you. It’s an interesting approach and I’ll be following the development of this module closely.
Useful resources
-
Progressive Web Apps: the future of Apps (20 minute video) - a good introduction to progressive web apps in general
-
Offline Cookbook by Jake Archibald - a thorough overview of different strategies for serving up resources offline
-
Instant Loading: Building offline-first Progressive Web Apps - video from Google I/O 2016
-
Making A Service Worker: A Case Study - article from Smashing Magazine
-
Mozilla Devloper Network has really good documentation on the APIs (not only for this, lots of other web technologies too)